My Fellow Americans...
Analyzing National Convention Speeches Using Python and NLTK
This is the first post in a series that will examine convention speeches from the RNC and DNC. This post focuses on gathering the speech transcripts, preparing them for analysis, and some initial analysis focused on a sample of DNC speeches. There is a Jupyter notebook available here. The plan will be to develop a function using a sample speech before downloading and cleaning the data. Once the function or functions are ready, I will download the all relevant speeches and begin the analysis.
Getting the transcripts
There are a lot of sources for transcripts of the speeches, and I wanted one source for all the speeches to create some consistency. Initially, I looked to the websites for the conventions, but the DNC's convention website lacked transcripts for several speeches. After looking at some news websites, I settled on Time Magazine. They had the advantage of (relatively) easily parsed web pages and (most importantly) they were laid out for consistently for each speech.
Examining the source for the page shows us that all of the transcript is contained within a blockquote tag. That will make this much easier. Using Beautiful Soup in Python, we can extract the text for the transcript using the following code:
r = requests.get(x)
soup = BeautifulSoup(r.text, 'lxml')
x = soup.select('blockquote')[0].get_text()
The above code downloads and parses the HTML in the first two lines and the third line extracts the text from the blockquote tag. The "[0]" returns the first instance and luckily the speech transcripts are always in the first blockquote tag. Without the "[0]", we would get a list which would add another step to our extraction. The .get_text() command extracts all the text from the blockquote section we identified Printing out the results shows us the speech text, some HTML junk (like '/n'), punctuation, and "(APPLAUSE)".
Cleaning the text
Now that we have the text, let's clean it up. A quick thank you to Kaggle for their post on text analysis, this was a really helpful article for guiding me in a lot of this analysis. First I will remove all of the weird punctuation and other symbols using a regular expression via the re package. I am not a regular expression expert, but the following line removes all non-letters from the data.
letters = re.sub("[^a-zA-Z]"," ", x)
words = letters.lower().split()
Now that we have just the letters, we can use .lower() and .split() to break the strings into words that are all lowercase. Putting everything into lowercase ensures that "family" and "Family" both get counted as the same word. Next, I remove stop words and repetitive words that lack a lot of meaning in this context.
stops = set(stopwords.words("english"))
meaningful_words = [w for w in words if not w in stops]
speech_words = ['thank', 'you', 'philadelphia', 'applause', 'hello']
words = [x for x in meaningful_words if x not in speech_words]
return( " ".join(words))
The first line loads stop words from the NLTK package. Stop words are common parts of speech that do not convey much meaning by themselves such as "to", "a", "the". Taking these out allows us to focus on more meaningful words in the analysis. (more info here) Additionally, I added words like "thank", "you", and "applause" to a list to be removed. They appear in every speech and are not adding much to this analysis. Lines two and four of the code remove the words from the speech if they are listed in either the variable "stops" or "speech_words". The final line joins everything back into a long string. The full function is below.
def speech_parser(x):
r = requests.get(x)
soup = BeautifulSoup(r.text, 'lxml')
x = soup.select('blockquote')[0].get_text()
letters = re.sub("[^a-zA-Z]"," ", x)
words = letters.lower().split()
stops = set(stopwords.words("english"))
meaningful_words = [w for w in words if not w in stops]
speech_words = ['thank', 'you', 'philadelphia', 'applause', 'hello']
words = [x for x in meaningful_words if x not in speech_words]
return( " ".join(words))
Word clouds!
While not the most scientific analysis, everybody loves a word cloud. Fortunately members of the Python community created a package, word_cloud, to accomplish this task. We can use the function above to pull the text for one of the speeches and then send it to word cloud.
url = 'http://time.com/4429984/dnc-hillary-clinton-speech-video-transcript/?iid=sr-link5'
z = speech_parser(a)
The above code parses the website and assigns it to the variable "z". Then I send z over to the word-cloud package.
from wordcloud import WordCloud
wordcloud = WordCloud(background_color='white', height = 400, width = 750).generate(z)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
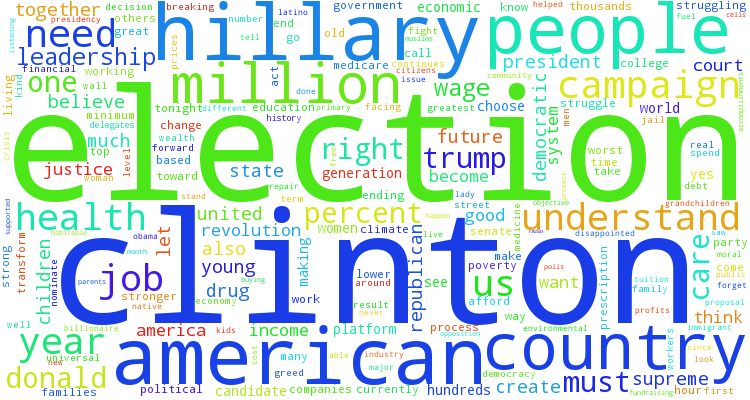
The above code creates the word-cloud with a white background. If you are using a Jupyter notebook, the size parameters in the package will be overridden by the notebook settings. However ".to_file()" can be added to the end of the first line to save the word-cloud to a file. The saved file will use the height and width parameters set in the function. It can be fun/informative to compare the word-clouds between speeches. Compare the above word-cloud with one from Sen. Cory Booker's speech.
url = 'http://time.com/4421756/democratic-convention-cory-booker-transcript-speech/?iid=sr-link10'
b = speech_parser(url)
wordcloud = WordCloud(background_color='white', height = 400, width = 750).generate(b).to_file('wc1.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
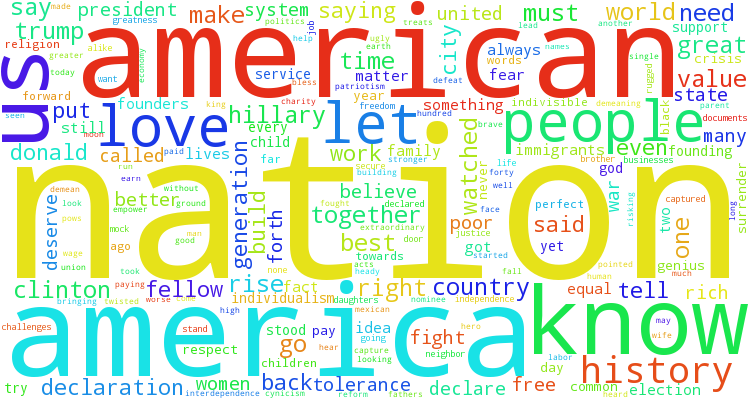
There are a lot more customization options in wordcloud. I recommend checking out the documentation for more information.
Frequent Terms
Next I'll examine the most frequent terms used in eight of the speeches. I hand selected a list of the speeches focused mainly on the headline speakers. Time's website had really weird search results and I gave up on an automated solution. I used the code below to pull together a list of lists containing the speech transcripts.
speech_list = [
'http://time.com/4426037/dnc-tim-kaine-speech-transcript-video/?iid=sr-link1',
'http://time.com/4426150/dnc-barack-obama-transcript/',
'http://time.com/4429984/dnc-hillary-clinton-speech-video-transcript/?iid=sr-link5',
'http://time.com/4421538/democratic-convention-michelle-obama-transcript/?iid=sr-link1',
'http://time.com/4421574/democratic-convention-bernie-sanders-speech-transcript/?iid=sr-link3',
'http://time.com/4425599/dnc-bill-clinton-speech-transcript-video/?iid=sr-link2',
'http://time.com/4426178/dnc-joe-biden-speech-transcript-video/?iid=sr-link7',
'http://time.com/4421756/democratic-convention-cory-booker-transcript-speech/?iid=sr-link10']
speeches = []
for url in speech_list:
speeches.append(speech_parser(url))
This code gives a lists within the speeches list for each of the eight speakers. We will analyze the most common and most interesting (defined very loosely) words within each speech. The speakers are Tim Kaine, President Obama, Hillary Clinton, Bernie Sanders, Michelle Obama, Bill Clinton, Joe Biden, and Cory Booker. Each speech is in its own list within the speeches list. First I will generate a list of the 5 most common terms in each speech using Scikit-learn's Count Vectorizer. The count vectorizer will not only count each word, but also will split our long text strings into individual words. I could have done this in the earlier scraping function, but that would have caused issues for the word-cloud package.
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
data = vec.fit_transform(speeches).toarray()
The above code generates a sparse matrix with each word, their respective counts for each speech, and converts the matrix to an array (for processing speed later). Rather than try to read this giant table, I will use the following code to print out the five top words for each speech. Thank you to Stack Overflow for the code used below.
fn1 = vec.get_feature_names()
for l in data:
print([(fn1[x]) for x in (l*-1).argsort()][:5])
The above code sorts the array and prints out the top five terms for each speech. You can easily modify the code above to print any number of terms. Each speech will appear in a separate list in the order they were saved by the speech_parser function. I have manually created the table below that shows each term's count.
| Speaker | Terms |
|---|---|
| Kaine | 'trump', 'donald', 'believe', 'kaine', 'ready' |
| Pres. Obama | 'america', 'hillary', 'people', 'every', 'years' |
| Hillary Clinton | 'people', 'us', 'america', 'country', 'know' |
| Michelle Obama | 'cheers', 'hillary', 'president', 'every', 'kids' |
| Sanders | 'election', 'clinton', 'hillary', 'people', 'country' |
| Bill Clinton | 'class', 'enough', 'political', 'tap', 'intending' |
| Biden | 'know', 'hillary', 'america', 'always', 'never' |
| Booker | 'nation', 'america', 'americans', 'us', 'love' |
No surprising results there. I do like how a lot of Bill Clinton's speech mentioned phrases about meeting/dating Hillary. The count vectorizer function has a lot of additional options I am not using in this example. Most notably it lets you use n-grams (groups of words appearing in a row of n length). I had tried this but ended up with a lot of repetitive results like 'Hillary', 'Clinton', 'Hillary Clinton', etc. While the results are interesting, we can also leverage more of sikit-learn's text processing features to look at the most unique words in each speech using TF-IDF.
TF-IDF is term document inverse document frequency. Basically, it is the number of times a word appears in a document (or speech in this case) divided by the number of times it appears in all documents. An exhaustive amount of detail is available at this Wikipedia article. Basically, words that are more unique to a given speech will get a higher score. This should reduce the repetition of words between speeches.
vectorizer = TfidfVectorizer(min_df=1)
speeches_tfidf = vectorizer.fit_transform(test)
This code, like before, creates a sparse matrix of terms with their TF-IDF score in place of their raw count. Again, this package has more options, like n-grams, that I will not be diving into in this tutorial. Below is code to print out the top eight words for each speech based on their TF-IDF score.
mat_array = speeches_tfidf.toarray()
fn = vectorizer.get_feature_names()
for l in mat_array:
print([(fn[x]) for x in (l*-1).argsort()][:8])
Thanks again to Stack Overflow for the code for this printing this out. I have manually recreated the table below.
| Speaker | Terms |
|---|---|
| Kaine | 'trump', 'ready', 'donald', 'believe', 'puede', 'se', 'si', 'kaine' |
| Pres. Obama | 'america', 'hillary', 'every', 'people', 'years', 'better', 'still', 'know' |
| Hillary Clinton | 'people', 'us', 'america', 'country', 'working', 'trump', 'know', 'believe' |
| Michelle Obama | 'cheers', 'every', 'kids', 'hillary', 'president', 'country', 'children', 'girls' |
| Sanders | 'election', 'clinton', 'hillary', 'people', 'country', 'campaign', 'percent', 'americans' |
| Bill Clinton | 'enough', 'tap', 'appropriately', 'thick', 'spring', 'glasses', 'introduce', 'magnetic' |
| Biden | 'know', 'jill', 'always', 'mean', 'hillary', 'america', 'say', 'folks' |
| Booker | 'nation', 'america', 'americans', 'rise', 'history', 'us', 'love', 'people' |
This has more insight. I especially enjoy Pres. Bill Clinton's terms 'glasses' and 'magnetic'. He spoke a lot about him and Hillary when they were younger and you can see that come through in the TF-IDF terms. The above code can be modified to show more terms, and could give more insights into the topics discussed. While it does a better job at finding interesting trends, TF-IDF can occasionally yield some weird results so be sure to take a close look at the results. Additionally, it falls into the same trap mentioned above with repetitive/redundant phrases, but does a much better job than raw counts.
There are some additional text processing steps beyond the scope of this example. Stemming can be applied to words to reduce redundancy by transforming words like 'runs' and 'running' into 'run'. Additionally, we can add n-grams to the analysis as I mentioned earlier. I will plan to cover some of these additional topics in the future.
In the next installment on convention speeches, I will look at some speeches from the RNC and introduce topic modeling. Can we identify common topics within the speeches? Do the topics differ from what was spoken about at the DNC? (hint, they do).
Comments
comments powered by Disqus