Using Data to Find Influential Twitter Followers

Courtey of XKCD
For campaigns or non-profit, getting useful insights out of Twitter (or any social media) sucks. Most paid services are just glorified bar graphs, or they require too large of scale in both reach and cash. In this post, I will walk through how to mine your Twitter followers to find those who have large numbers of their own followers. Once you find these influencers, you can reach out or target them for more follow-up to help spread your message to their audience. Basically, it's influencer marketing (only with less pyramid scheme baggage) using data science to help you figure out who to target to get your message out.
Codecentric recently mined their Twitter followers to graph where their influencers were. For a technical walkthrough of the process, I highly recommend checking out their blog post. It gives a great overview. I will be using their code as the basis for my application and analysis. With permission, I will be using Ben Hanson for Congress as the case study. Full disclosure, Ben is a friend and we previously worked together on campaigns. First I will go through using the data and then walkthrough how to create the analysis.
The Data
I pulled together a list of Ben Hanson for Congress followers and their followers. From this list of 2nd degree followers, I pulled in all of the descriptions in their profiles and used Latent Dirichlet Analysis to look for common topics between the different descriptions. This allowed me to look for groups of followers with similar interests. By looking at followers of followers, we identified primary followers who have large networks of followers who are not yet following us. A communications or field staffer can reach out and message them directly. Since the topics are color coded, you can customize the message the potential audience.
Below is a wordcloud color coded by each of the five topics. Looking at the words we can see there is a lot of similarity between a few of the groups, which is common in real-world applications of LDA. Below is my quick summary of the topics.
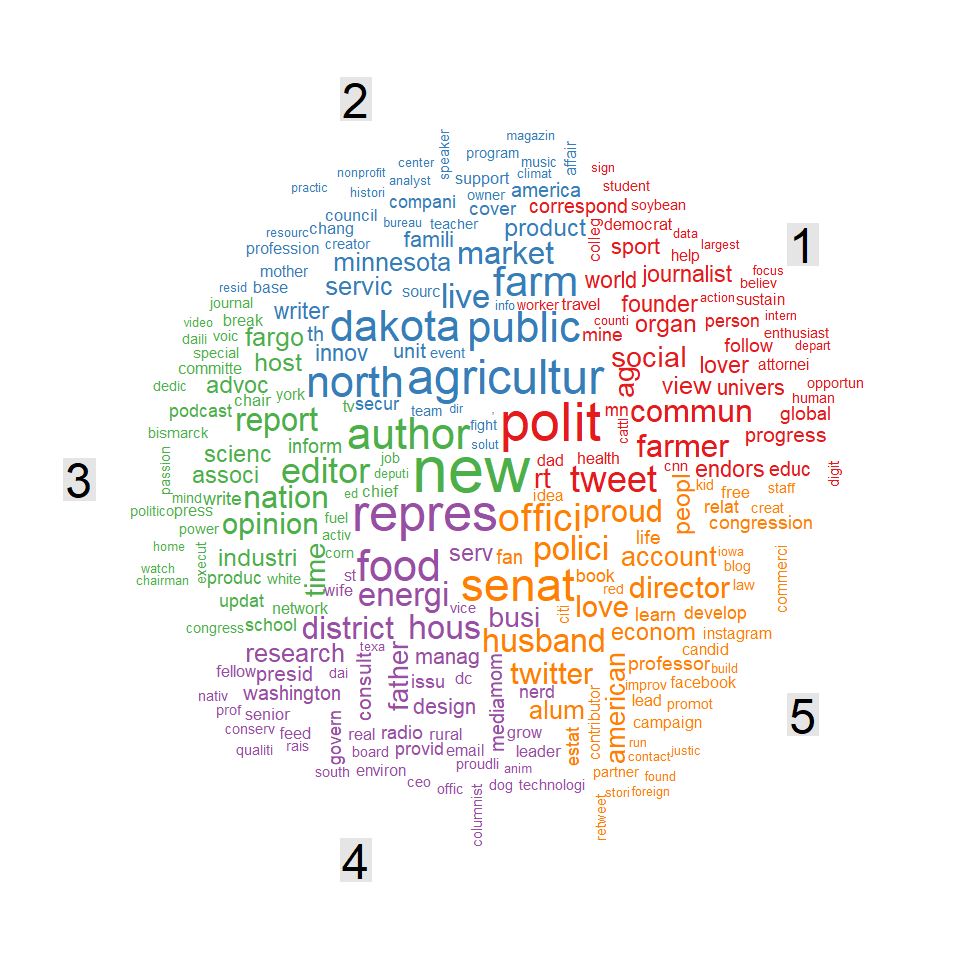
- Community minded farm/agriculture/local political topics
- North Dakota and Minnesota professionals
- News and op-ed focused accounts
- Political issue focused accounts
- Official accounts including government, teaching, and self-employed
Next is a graph showing the 2nd degree followers (friends of friends). The goal is to look for people who are bridges to larger groups of potential followers. The circled sections show good examples of Twitter followers with broad reach who should be pulled into a list to contact. I have purposely left the names off of this version to preserve their privacy.
Finally, this graph has each of the points color coded to show the topic (from above chart) that their Twitter description matches best. This helps visually highlight if there were pockets of common interests among the Twitter followers. In this example, the topic points are evenly spread out, but it never hurts to check.
Once you have your list of people, it is about actually engaging them directly (ideally on topics they already care about). You and/or your communications staff can review their posts to find areas of similar interests. Depending on resources (mainly time and staff), you can reach out directly via Twitter or email. You can also start crafting content such as tweets or YouTube videos with messages that are likely to resonate with your targeted accounts and their followers.
Rather than try to drown everyone with reposts of old talking points, you can specifically engage individuals on topics they are already interested in. By prioritizing followers with a large potential audience, you can engage their followers with similar interests. For cash strapped campaigns and non-profits, this can be a very affordable way to get your message to a wider audience. Even if you have the resources for broad based advertising, this is still a great way to engage people where they already are on topics they already care about. This genuine interaction fosters a feeling of authenticity and connection with your supporters, a fact too often overlooked in an era of email spam and Twitter bots. Actual human interaction around shared interests/topics are especially persusasive.
Conducting the analysis
The first step is to sign up as a Twitter developer here and getting your credentials. [Here] is a great overview by XXXX on working with the Twitter API. I will be using the twitteR package to work with Twitter's data feed.
setup_twitter_oauth(consumer_key = consumerKey,
consumer_secret = consumerSecret,
access_token = accessToken,
access_secret = accessSecret)
Once I set up a login, I downloaded screen names and descriptions of Ben's followers from the Twitter feed.
user <- getUser("BenjaminWHanson")
friends <- user$getFriends()
friends_df <- twListToDF(friends) %>%
rownames_to_column()
followers <- user$getFollowers() # my followers
followers_df <- twListToDF(followers) %>%
rownames_to_column()
Then I iterate over that list of followers and pull in their followers' names and descriptions to get a second degree friend network. This is the potential audience of people not currently following Ben that we would like to target with his message.
for (i in 1:length(friends)) {
friends2 <- friends[[i]]$getFriends() # my friends' friends
friends2_df <- twListToDF(friends2) %>%
rownames_to_column() %>%
mutate(friend = as.character(friends[[i]]$id))
if (i == 1) {
friends2_df_final <- friends2_df
} else {
friends2_df_final <- rbind(friends2_df_final, friends2_df)
}
print(i)
}
The packages tidytext and SnowballC helped me to clean up the text fields. Words like 'a', 'the', 'or', etc. are known as stopwords and do not add a lot of value to the analysis and so they are removed. The next step is to cut similar words to their "stem". For example, "running" and "runner" will be shortened to "run". The SnowballC package performs this stemming and more information on that process can be found here.
Now that the data is cleaned up we can group common topics from the descriptions using Latent Dirichlet Analysis. Basically this process groups together similar documents (in this case, descriptions) based on the combination of words they use. I set the model up to find 5 topics, but that parameter can be adjusted as needed.
Finally, the data is pulled into an edge graph to show connections between everyone in this Twitter mini-universe. The igraph package in R provides a useful interface for this. The code below takes the connections queried earlier, and puts them into an edge list for use in network analysis.
edge_table_1 <- data.frame(source = rep("BenjaminWHanson", nrow(friends_df)),
target = friends_df$screenName)
edge_table_2 <- data.frame(source = followers_df$screenName,
target = rep("BenjaminWHanson", nrow(followers_df)))
edge_table_3 <- data.frame(source = friends2_df_final$screenName.y,
target = friends2_df_final$screenName.x)
edge_table <- rbind(edge_table_1, edge_table_2, edge_table_3)
From here you can use igraph's graphing function to create the graph shown above and save it as a PDF.
graph <- graph_from_data_frame(edge_table, directed = TRUE)
layout <- layout_with_fr(graph)
pdf("twitter_net.pdf", width = 70, height = 80)
plot(graph,
layout = layout,
vertex.label = V(graph)$label,
vertex.color = scales::alpha(V(graph)$color, alpha = 0.5),
vertex.size = V(graph)$size ,
vertex.frame.color = "gray",
vertex.label.color = "black",
vertex.label.cex = 10,
edge.arrow.size = 1)
dev.off()
To highlight the potential targets, I used inkscape to modify the pdf manually. It just seemed easier than trying to do this in R, though I'm sure there is a way. If this is something you are interseted in exploring further, it is worth looking into Gephi, a network visualization program. It has a lot of additional features for creating examining these sort of visualizations.
Now go out there and find your influential followers on Twitter.
Comments
comments powered by Disqus